CamlCATE(self, df, Y, T, X, W=None,*, discrete_treatment=True, discrete_outcome=False, seed=None,)
The CamlCATE class represents an opinionated framework of Causal Machine Learning techniques for estimating highly accurate conditional average treatment effects (CATEs).
CamlCATE is experimental and may change significantly in future versions.
The CATE is defined formally as \(\mathbb{E}[\tau|\mathbf{X}]\) where \(\tau\) is the treatment effect and \(\mathbf{X}\) is the set of covariates.
This class is built on top of the EconML library and provides a high-level API for fitting, validating, and making inference with CATE models, with best practices built directly into the API. The class is designed to be easy to use and understand, while still providing flexibility for advanced users. The class is designed to be used with pandas, polars, or pyspark backends, which ultimately get converted to NumPy Arrays under the hood to provide a level of extensibility & interoperability across different data processing frameworks.
The primary workflow for the CamlCATE class is as follows:
Initialize the class with the input DataFrame and the necessary columns.
Utilize flaml AutoML to find nuisance functions or propensity/regression models to be utilized in the EconML estimators.
Fit the CATE models on the training set and select top performer based on the RScore from validation set.
Validate the fitted CATE model on the test set to check for generalization performance.
Fit the final estimator on the entire dataset, after validation and testing.
Predict the CATE based on the fitted final estimator for either the internal dataset or an out-of-sample dataset.
Summarize population summary statistics for the CATE predictions for either the internal dataset or out-of-sample predictions.
For technical details on conditional average treatment effects, see:
Note: All the standard assumptions of Causal Inference apply to this class (e.g., exogeneity/unconfoundedness, overlap, positivity, etc.). The class does not check for these assumptions and assumes that the user has already thought through these assumptions before using the class.
The input DataFrame representing the data for the CamlCATE instance.
required
Y
str
The str representing the column name for the outcome variable.
required
T
str
The str representing the column name(s) for the treatment variable(s).
required
X
str | list[str]
The str (if unity) or list of feature names representing the feature set to be utilized for estimating heterogeneity/CATE.
required
W
str | list[str] | None
The str (if unity) or list of feature names representing the confounder/control feature set to be utilized only for nuisance function estimation. When W is passed, only Orthogonal learners will be leveraged.
None
discrete_treatment
bool
A boolean indicating whether the treatment is discrete/categorical or continuous.
True
discrete_outcome
bool
A boolean indicating whether the outcome is binary or continuous.
The input DataFrame representing the data for the CamlCATE instance.
Y
str
The str representing the column name for the outcome variable.
T
str
The str representing the column name(s) for the treatment variable(s).
X
Iterable[str]
The str (if unity) or list of variable names representing the confounder/control feature set to be utilized for estimating heterogeneity/CATE and nuisance function estimation where applicable.
W
Iterable[str] | None
The str (if unity) or list of variable names representing the confounder/control feature set to be utilized only for nuisance function estimation, where applicable. These will be included by default in Meta-Learners.
discrete_treatment
bool
A boolean indicating whether the treatment is discrete/categorical or continuous.
discrete_outcome
bool
A boolean indicating whether the outcome is binary or continuous.
available_estimators
str
A list of the available CATE estimators out of the box. Validity of estimator at runtime will depend on the outcome and treatment types and be automatically selected.
model_Y_X_W
sklearn.base.BaseEstimator
The fitted nuisance function for the outcome variable.
model_Y_X_W_T
sklearn.base.BaseEstimator
The fitted nuisance function for the outcome variable with treatment variable.
model_T_X_W
sklearn.base.BaseEstimator
The fitted nuisance function for the treatment variable.
<econml.dr._drlearner.LinearDRLearner object at 0x7f0733bbb280>
[('LinearDML', <econml.dml.dml.LinearDML object at 0x7f0733bb8a00>), ('NonParamDML', <econml.dml.dml.NonParamDML object at 0x7f0733bba200>), ('CausalForestDML', <econml.dml.causal_forest.CausalForestDML object at 0x7f0733bbba00>), ('LinearDRLearner', <econml.dr._drlearner.LinearDRLearner object at 0x7f0733bbb280>)]
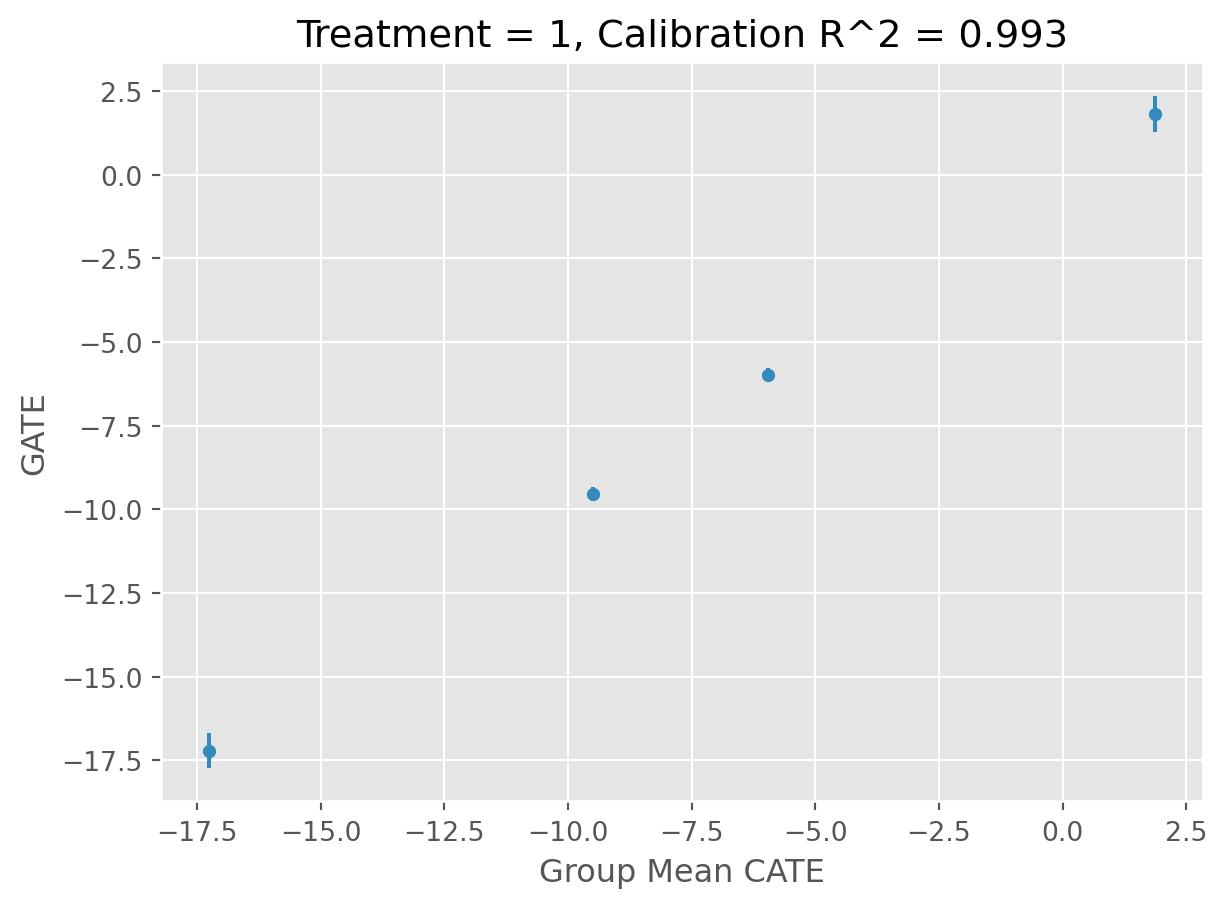
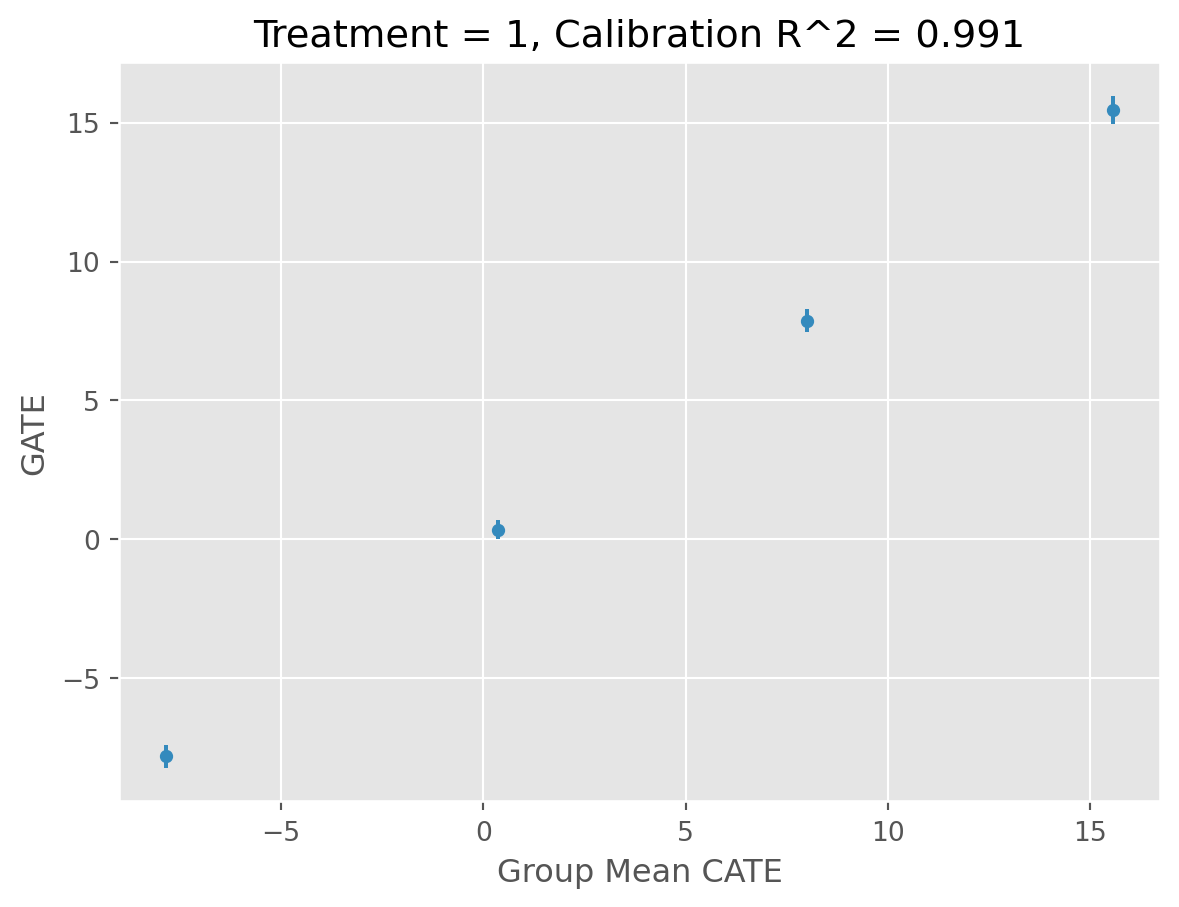
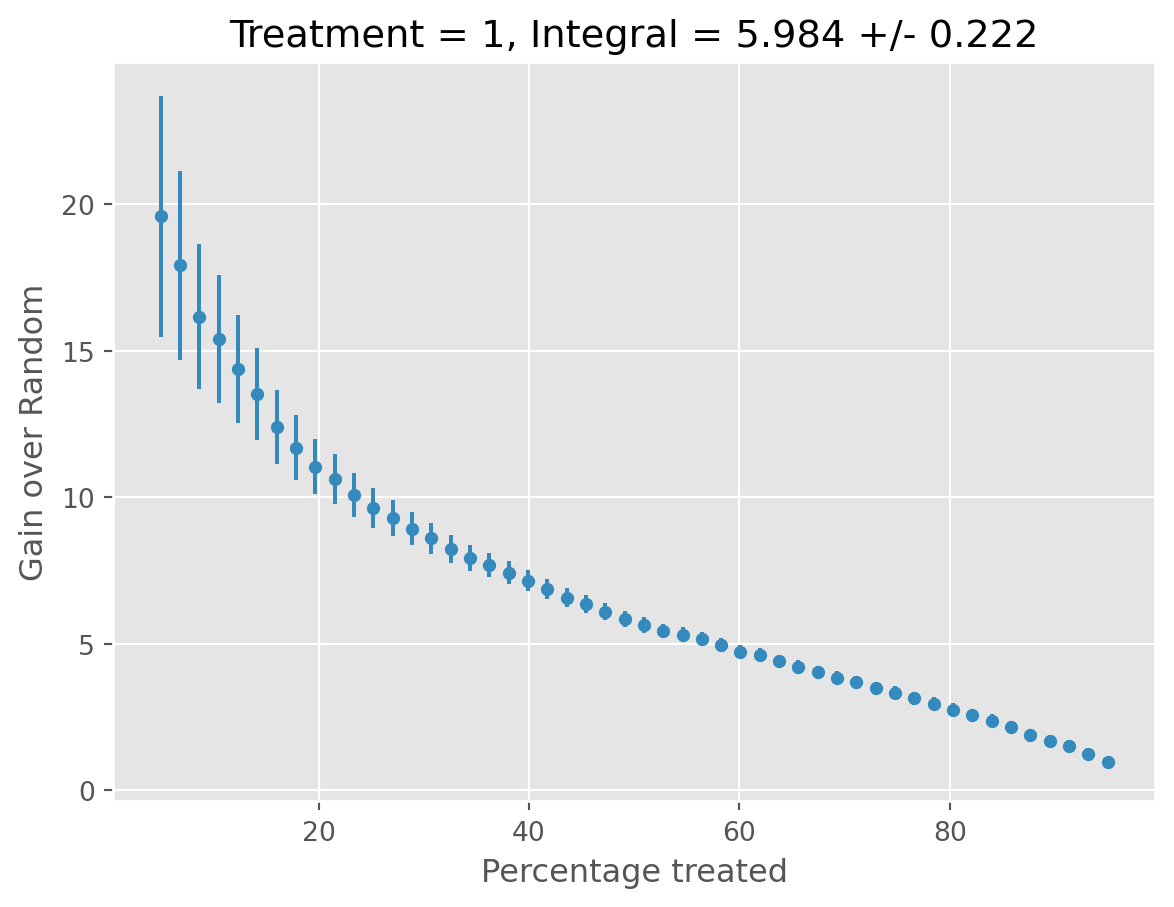
Validates the fitted CATE models on the test set to check for generalization performance.
Uses the DRTester class from EconML to obtain the Best Linear Predictor (BLP), Calibration, AUTOC, and QINI. See EconML documentation for more details. In short, we are checking for the ability of the model to find statistically significant heterogeneity in a “well-calibrated” fashion.
Sets the validator_report attribute to the validation report.
Parameters
Name
Type
Description
Default
n_groups
int
The number of quantile based groups used to calculate calibration scores.
4
n_bootstrap
int
The number of boostrap samples to run when calculating confidence bands.
100
estimator
BaseCateEstimator | EnsembleCateEstimator | None
The estimator to validate. Default implies the best estimator from the validation set.
None
print_full_report
bool
A boolean indicating whether to print the full validation report.
Predicts the CATE based on the fitted final estimator for either the internal dataset or provided Data.
For binary treatments, the CATE is the estimated effect of the treatment and for a continuous treatment, the CATE is the estimated effect of a one-unit increase in the treatment. This can be modified by setting the T0 and T1 parameters to the desired treatment levels.
Parameters
Name
Type
Description
Default
X
pandas.DataFrame | np.ndarray | None
The DataFrame containing the features (X) for which CATE needs to be predicted. If not provided, defaults to the internal dataset.
None
T0
int
Base treatment for each sample.
0
T1
int
Target treatment for each sample.
1
T
pandas.DataFrame | np.ndarray | None
Treatment vector if continuous treatment is leveraged for computing marginal effects around treatments for each individual.
None
Returns
Name
Type
Description
np.ndarray
The predicted CATE values if return_predictions is set to True.
Provides population summary statistics for the CATE predictions for either the internal results or provided results.
Parameters
Name
Type
Description
Default
cate_predictions
np.ndarray | None
The CATE predictions for which summary statistics will be generated. If not provided, defaults to internal CATE predictions generated by predict() method with X=None.